1. 这篇文章究竟讲了什么问题?
如何利用 GPU 来并行加速大规模的网格处理
2. 这个问题的性质是什么?如果不完全是一个新问题,那为什么它“仍然重要”?
属于改进类的问题
以往的网格加速方法要么是:
- application-specific
- 需要从线性代数上对问题进行 reform
- mesh 会变为稀疏矩阵
- 减少了中间变量,但是局部性变差,性能不够好
所以需要一个通用的高性能加速框架
3. 这篇文章致力于证明什么假设?
通过高效的数据结构 + 更好的变成模型,可以实现通用的网格处理加速
4. 有哪些与这篇文章相关的研究?
- 高性能编程模型
- 图像处理:Halide,调度与算法分离
- 稀疏体素计算 / simulation:太极
- 纯模拟:Ebb
- 图处理:Gunrock
5. 这篇文章提出的问题解决方案中,核心贡献是什么?
一个 high-level 的编程模型
用户顶层
定义好每个 mesh 上执行的计算
八种查询

以计算 vertex normal 为例:

非常清晰
模型底层
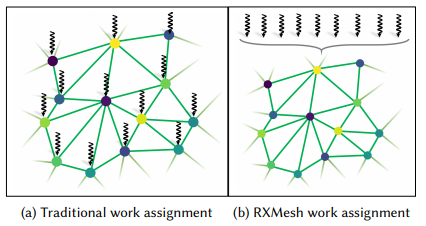
通过将整个 mesh 切分成很多 patch,然后按照 patch 来往 GPU 的 block 上分配计算任务,进而增加了局部性
patching 之后的 index 可视化出来如下图,很明显,比起直接按照 global sorting 的划分,patching 下相同 index 的部分会更加集中,相关数据在查询、计算的时候可以常驻 shared memory

那么 patch 如何表示?
作者选用了 LAR (Linear Algebraic Representation) 来表示每个 patch
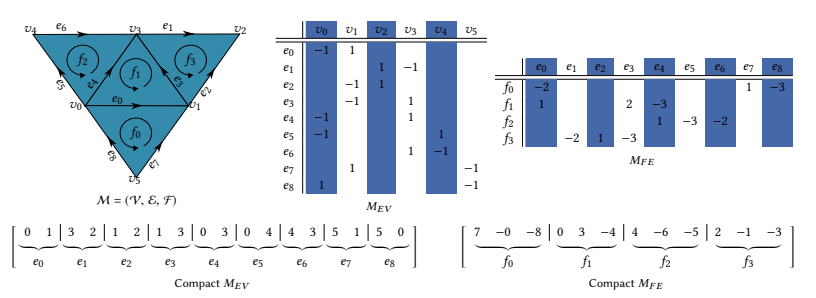
这样的表示更加紧凑
- 另外因为每个 patch 其实不大,所以每个 patch 内的信息都可以使用 16-bit 来表示,使得数据更加紧凑
负载均衡
设计了类似任务队列的机制,block 内的 thread 不与 vertex 绑定,而是采用协作的模式,使得各个 thread 的负载较为均匀
ribbon 机制
为了减少 block 之间的通信开销,每个 patch 会额外增加边上的一圈网格,从而无需从其他 patch 取计算结果
6. 实验是如何设计的?
- 查询操作(对比通用性能)
- 与 PDE、OpenMesh、CGAL 等业界库对比性能
- 应用(对比特定应用性能)
- Mean Curvature Flow
- Geodesic Distance
- Bilateral Filtering
- Vertex Normal
7. 实验是在什么样的数据集基础上运行的?
网格取自 Thingi10K: A Dataset of 10,000 3D-Printing Models
8. 实验结果能否有力地支持假设?
- 通用查询
- 速度吊打 OpenMesh 和 CGAL
- 一些场景比 PDE 略慢
- 比如 EV、EF 的时候,因为 PDE 只需要写 4-bytes per-thread,所以快不少
- 特定应用
- Mean Curvature Flow
- 4.6x faster than PDE
- Geodesic Distance
- 15.5x faster than PDE
- Bilateral Filtering
- 因为 RXMesh 需要读 ribbon,多读了
- PDE 比 RXMesh 快 1.12x
- Vertex Normal
- hardwired Indexed triangle 比 RXMesh 快 1.14x
- 因为 Mesh Matrix / hardwired version 的内存更加规整
- 每个面只读三个顶点,一点都不多读
- 即便如此,RXMesh 速度还是不错的,毕竟写起来简单多了而且是通用方法
- Mean Curvature Flow
- 两组实验都充分表明了 RXMesh 的优越
9. 这篇文章的贡献是什么?
一个通用的、高性能的、高级的网格数据处理编程模型
作者在 slide 里补充了一句作为结论: Programmer-managed caching is the right way to capture mesh locality and improve GPU performance for mesh processing
10. 下一步可以做什么?
- 支持动态网格
- 现在的加速结构需要对每个 mesh 进行一次构造
- 需要想办法支持动态改变的网格
- 增强 high-order 查询的性能
- 现在都是一级的查询(8种)
- 支持 quad mesh
- 现在全都是三角网格
- 也许之后还可以支持体积网格