1. 这篇文章究竟讲了什么问题?
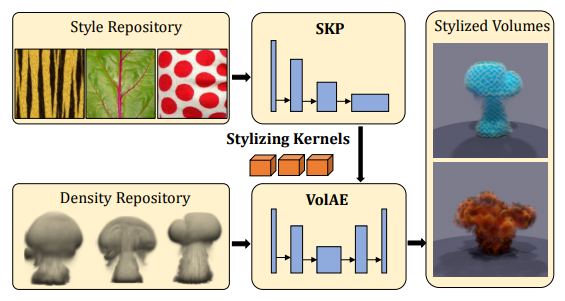
通过体积风格转移的方法,来高效地构造颜色外观上符合要求的、异质单反射体积。
网络使用了一个体积的自编码器,并且使用了 stylizing kernel predictor
2. 这个问题的性质是什么?如果不完全是一个新问题,那为什么它“仍然重要”?
属于改进性质的问题,之前已经有不少人研究过了体积上的风格迁移,但是文章提出的方法能够得到更好的效果。
同时这篇 paper 也属于 Artistic Appearance Design,传统的方法需要较为复杂的人工调整才能得到较好的效果,而本文的方法不需要人工干预,效率更高。
3. 这篇文章致力于证明什么假设?
证明它的这套风格迁移的框架是 work 的,并且效果很好
4. 有哪些与这篇文章相关的研究?
- Neural Style Transfer for Images
- Neural Style Transfer for 3D Contents
- Artistic Appearance Design
- Differentiable Rendering
5. 这篇文章提出的问题解决方案中,核心贡献是什么?
核心 idea
- 提出了一个将颜色外观从二维图形转移到三维图形上的框架
细节
设计了一个多尺度的基于 kernel 的神经网络来进行任意的风格迁移并保证时间上的一致性
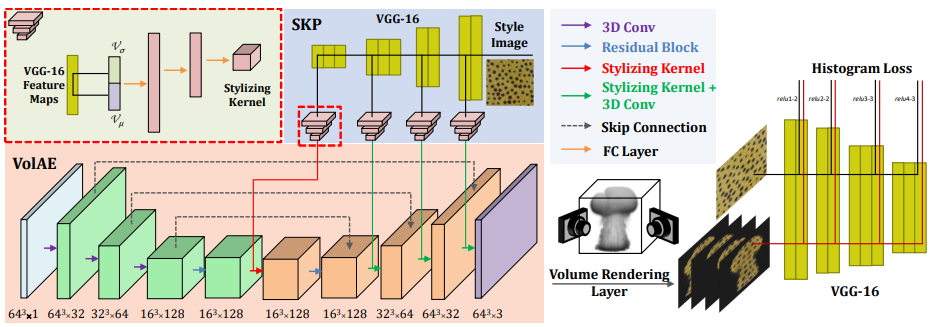
- SKP
- 首先使用 CNN (VGG) 来提取多个尺度的二维图片上的特征
- 然后选用 channel-wise 的均值和方差(实际网络中用的是标准差)进行拼接,得到一个特征向量
- 将这个向量通过一系列全连接层映射到一个 kernel 上
- VolAE
- 经典的 encoder-decoder 结构,中间带有 skip 连接
- 在 decode 阶段将前面 SKP 得到的 kernel 插入进来,来将二维的风格加入到生成的体积中
- SKP
引入了一个密度感知的 instance normalization 层,来避免色彩偏移
色彩偏移 / 色差
为什么会出现色彩偏移?
- 在一些场景里(比如烟雾模拟),voxel 的分布非常不均匀,一些稀疏却非常致密的 voxel 会导致训练困难,进而产生色彩偏移
解决
使用 DAIN (density-aware instance normalization) 来给这一部分的 voxel 更大的权重
加入了一个平滑的密度 mask: $\textbf{m} = 1 - \text{exp}(-\lambda\textbf{V}_\sigma^2)$
于是均值和方差变为:
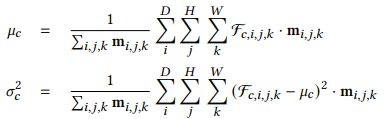
效果

实现了一个分析性的可微体积渲染层,这样可以方便 loss 的计算
分析性 → 简化模型
假设
- 物体的相位函数是各项异性的,且只被环境光照亮
- 每个 pixel 上只发射一条光线,且只考虑一次散射
简化模型
- ray marching 的 sample 是等距离的
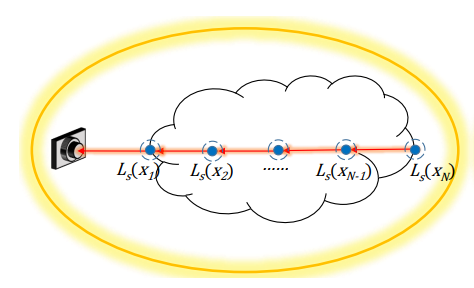
- 每次 sampling 的辐射度都是从各向异性的相位方程中采样出来的
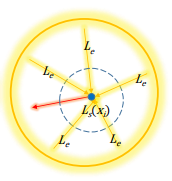
光源使用环境光,这样可以渲染出比较均匀的体积,避免网络将点光源产生的阴影当作特征进行学习
不使用通用的 DTRT 框架,因为太慢了
Loss
- Gran Loss 不好
- 收敛慢
- 有 artifacts
- 用 Histogram Loss
- 另外加上了 total variation loss 和 temporal loss,前者是正则化项,来增强空间平滑性,后者是时域上的平滑性
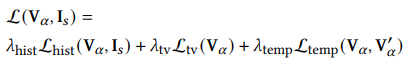
- Gran Loss 不好
6. 实验是如何设计的?
- 使用 pytorch 实现了整个网络,并与以前的方法进行对比
- 对比不同的 loss function 的效果
- 对比不同的 kernel、views 的效果
- 尝试各种场景的 demo
7. 实验是在什么样的数据集基础上运行的?
- volume 数据集
- 使用 mantaflow 生成了大量体积数据集
- simulate 100 groups of smokes with a resolution of 64 × 64 × 64
- 20 * 128 x 128 x 128
- 避免网络对低分辨率的体积过拟合
- 增加鲁棒性
- style image 数据集
- DTD 数据集
8. 实验结果能否有力地支持假设?
与传统方法对比是投票投出来的
- user study

b. 不过确实,风格迁移不太好有非常量化的评价指标,毕竟不存在 ground truth
loss 效果好
histogram loss 最符合输入图片的色彩分布

temporal loss
加上之后可以消除 flicker
不同的 kernel

作者对比了一大堆,但是毕竟我们也不知道 ground truth,所以其实只是呈现了一些不同的效果
训练所用的视角数量
越多越好,符合直觉

其他 demo
- 通过调整 volume 的分辨率可以调整风格结构的尺寸
- 这套方法能够模拟玉石这种半透明材料
- 只要输入的风格图片是真实世界中的半透明材料上采集的即可
- 可以模拟动态的火焰
9. 这篇文章的贡献是什么?
- 提出了一个将颜色外观从二维图形转移到三维图形上的通用框架
- 设计了一个多尺度的基于 kernel 的神经网络来进行任意的风格迁移,并保证了时域上的一致性
- 引入了一个 DAIN 层,来避免色彩偏移
- 实现了一个简化的可微体积渲染层,方便 loss 的计算,提高训练效率
10. 下一步可以做什么?
- 缺少细节
- 比如毛发、纤维这种都还不行
- 因为直接使用的是均值和方差,可能需要补充更多的统计信息
- 没法对体积本身进行同时的风格迁移
- 尝试套用 TNST,但是效果并不是很好
- 需要探索一种联合迁移优化的方案